Cookie settings
We use cookies to analyze user behavior in order to improve the website for you.
By Erland Grimstad on Apr 14, 2023
NB! Blogginnlegget kan inneholde skadelig innhold som rasisme, sexisme, og andre trakkaserende beskrivelser.
Klikk på bildene for å få interaktive figurer.
Click here to read the blog post in English.
Målet til Abdera for moderering av kommentarer på nettet er en tilsynelatende enkel oppgave, men krever en mer omfattende tilnærming enn å bare bruke et ordfilter for å skille “gode” ord fra “dårlige” ord. Selv om denne metoden brukes av mange store sosiale medier-sider, har den flere begrensninger: den er ikke robust nok til å håndtere språklige inkonsekvenser som dialekt, skrivefeil og variasjoner i staving, den kan overse støtende innhold med ord som ikke er i filterlisten, og den kan produsere falske positiver ved å være overfølsom for visse ord. Som et resultat har menneskelig moderering vært en nødvendighet for de fleste sider som ønsker å fortsette å ha offentlige kommentarfelt.
Hos Abdera er vi dedikerte til å utvikle avanserte AI-baserte modererings- og analyseverktøy. Vi anerkjenner viktigheten av kommentarfelt på nettet i offentlige debatter, men når disse diskusjonene blir mer tilgjengelige, øker sannsynligheten for upassende innhold. Økningen av generativ AI som ChatGPT og Dall-E har bare akselerert denne trenden.
Imidlertid mener vi at responsen fra store medieaktører om å stenge kommentarfeltene er kontraproduktiv. Denne tilnærmingen presser brukere mot mindre fora og ekkokamre, og kveler den sunne utvekslingen av ulike meninger.
Vi mener at verdien av effektiv moderering ligger ikke bare i å oppdage og fjerne støtende innhold, men også i å forstå hvordan sosiale medier-brukere engasjerer seg med og reagerer på ulike typer innhold. På den måten sørger man for at den kontinuerlige demokratiske prosessen med offentlig tilbakemelding og medierespons fungerer som den skal.
I dette blogginnlegget har vi organisert et sett med interaktive grafer som oppsummerer 40 000 anonymiserte sosiale medier-kommentarer på norsk (med klassifisering av hatprat) etter deres emner og nøkkelord. Av hensyn til personvern er navnene på kommentatorer erstattet med NAVN (noe som gjør dette til et vanlig nøkkelord).
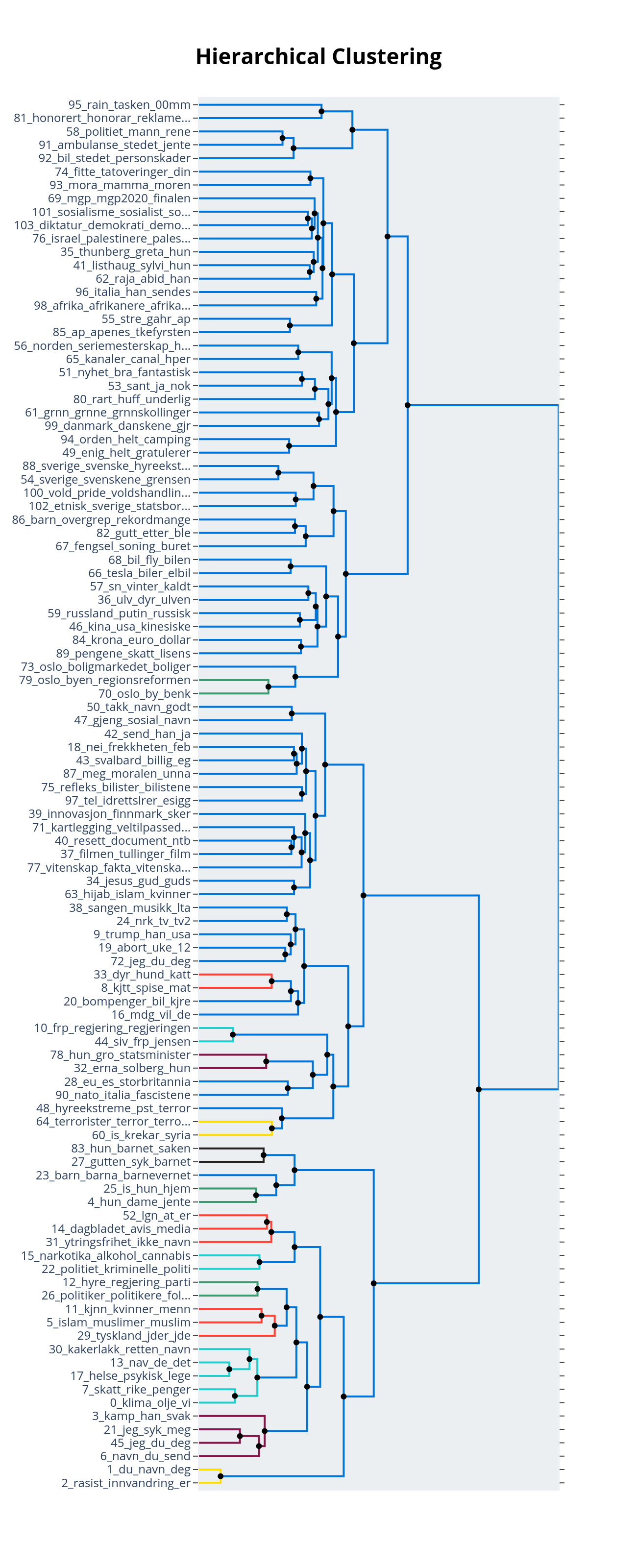
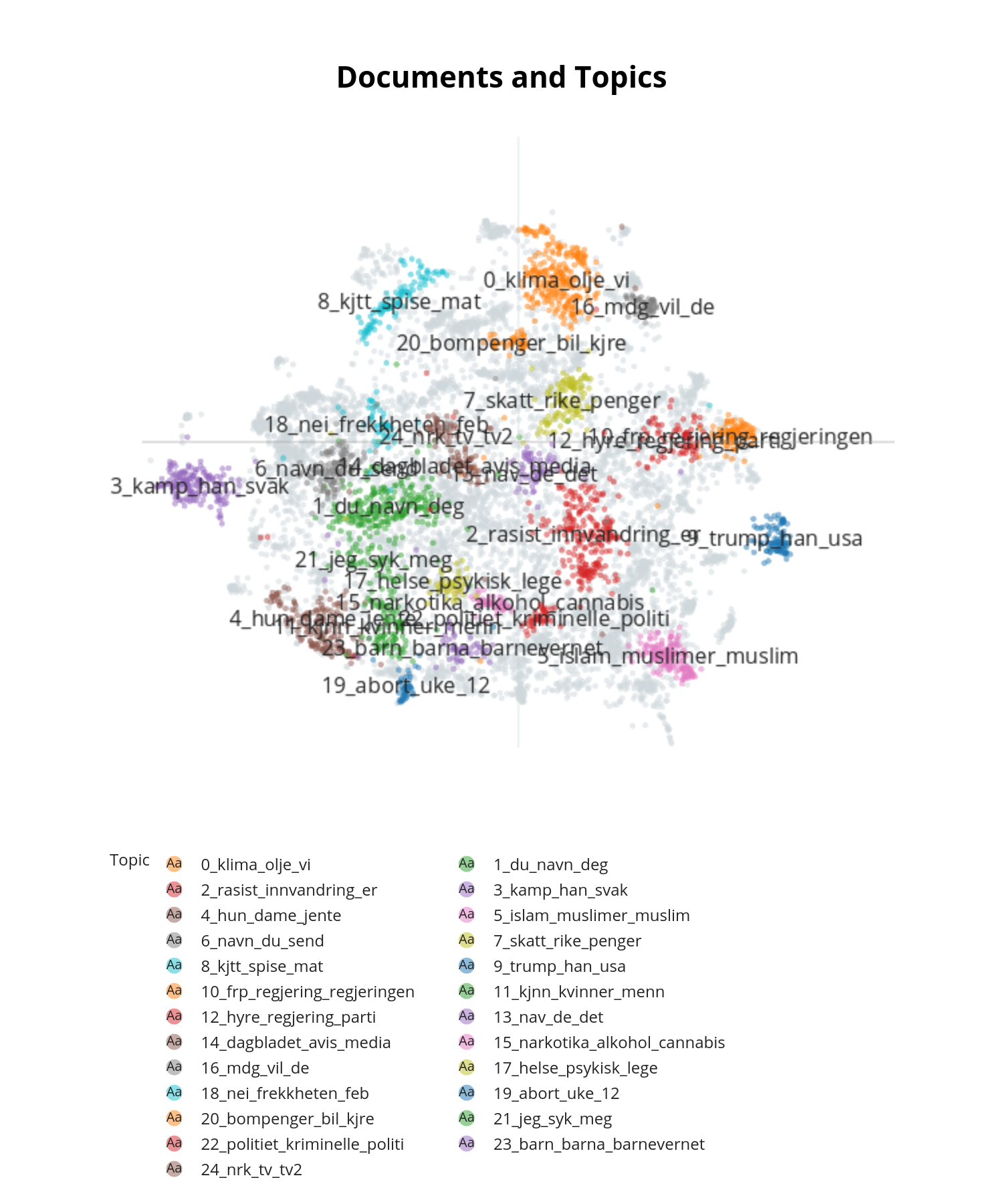
Den endelige emnestrukturen avslører noen overraskende (og mange lite overraskende) resultater. Som forventet viser figur 1 temaer som “101_sosialisme_sosialist_sosialister_eus_”, “103_diktatur_demokrati_demokratiet_et”, og “76_israel_palestinere_palestinerne_palestina”: alle omhandler vanlige politiske temaer. Disse temaene er igjen relatert til en kategori av politiske figurer “thunberg_listhaug_greta_raja_sylvi” og, litt mer overraskende, i mindre grad “69_mgp_mgp2020_finalen_mgpfinalen”. Hierarkiet kobler sammen emner som sterkt debatterte politiske hendelser, nyhetsartikler og vanlige fornærmelser (f.eks. “74_fitte_tatoveringer_din_hore” og “93_mora_mamma_moren_mi”).
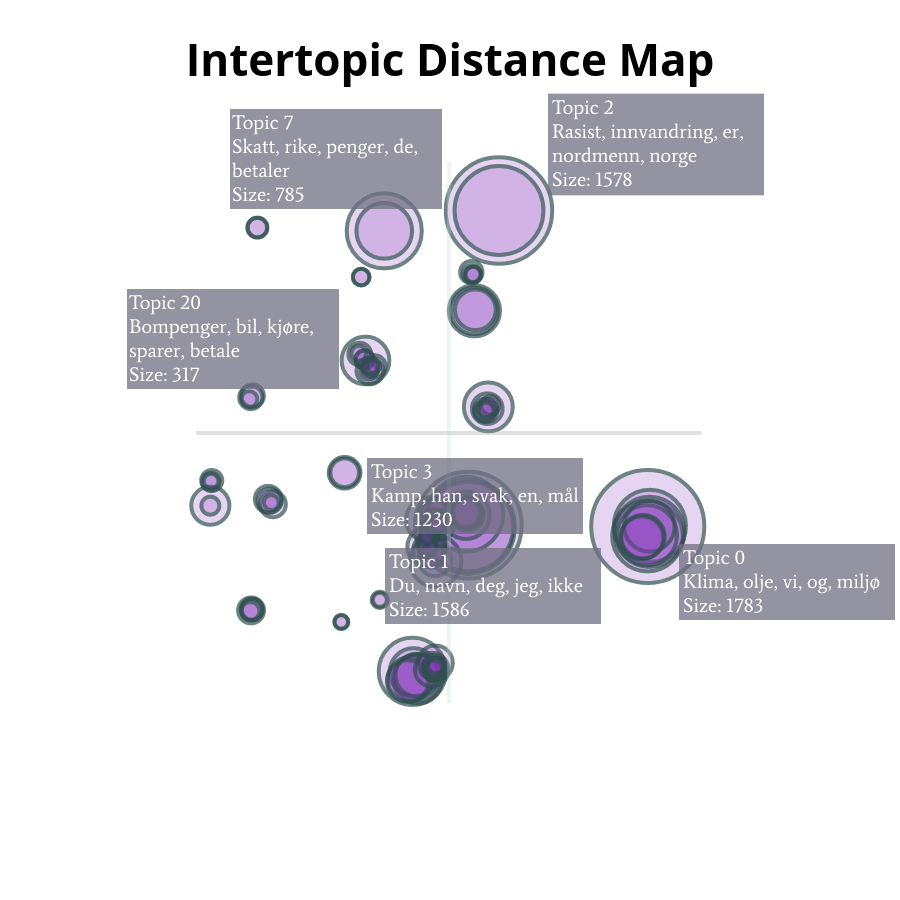
Figur 2 visualiserer disse trendene etter deres relative avstand. Vi observerer, for eksempel, at “5_islam_muslimer_muslim_er” overlapper fullstendig “2_rasist_innvandring_er_nordmenn”. Kanskje mer interessant er de ikke-overlappende temaene: temaene som er relatert indirekte i større grad. For eksempel, emnene 13 og 7 om rikdom og NAV (velferdsadministrasjon), samt emnene 5 og 2 – som direkte illustrerer en relasjon mellom temaene Islam, innvandring og religion med velferd. Tilsvarende er tilfellet med politi, rettssystem, narkotika, Islam og innvandrere, samt miljø, kjøtt, petroleum, MDG og FrP.
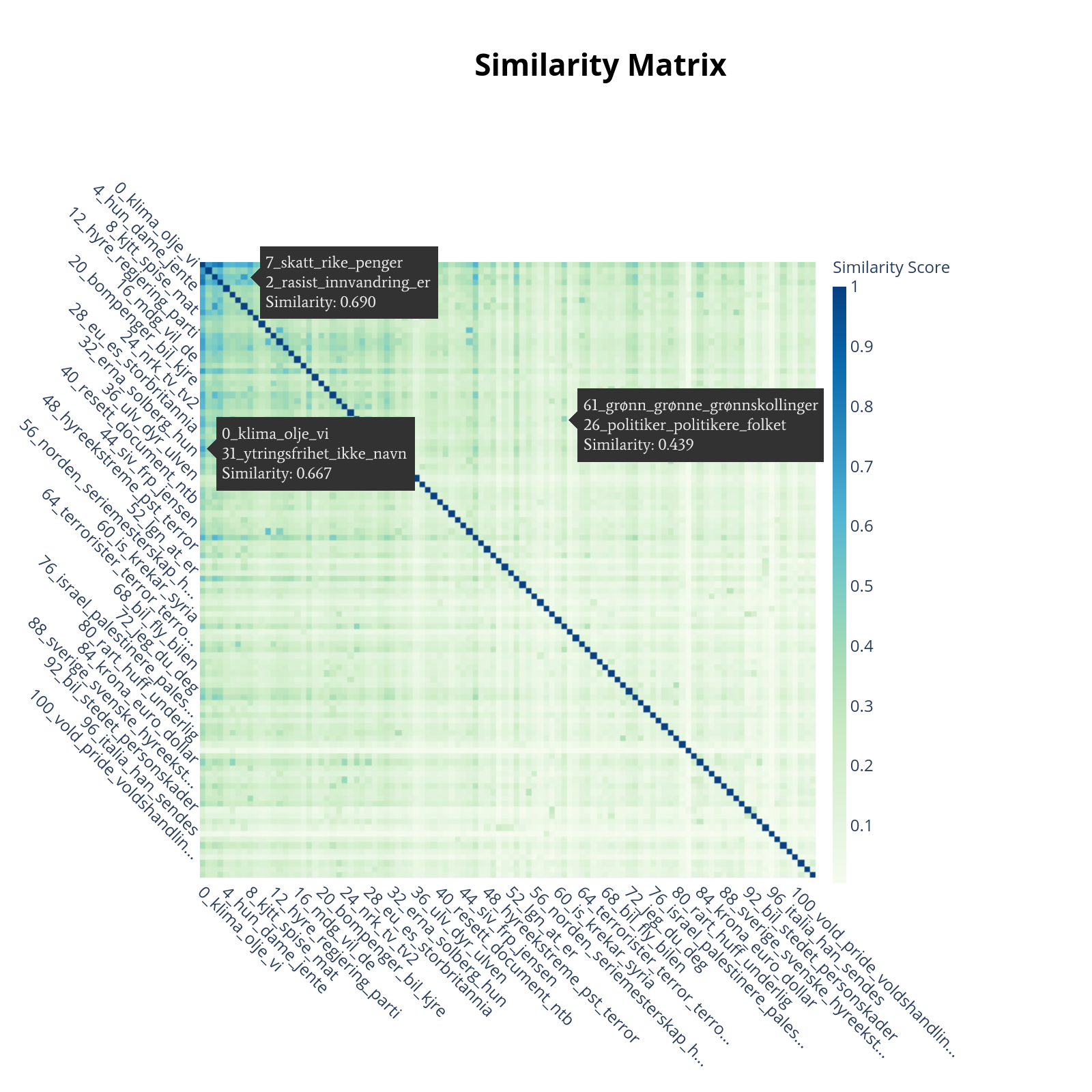
For å kunne gjenkjenne trender ordentlig, må vi etablere en grunnlinje for brukertilbakemeldinger. Figur 5 viser en kartlegging av dataene våre med emner som fargede klynger og hver kommentar som et datapunkt. Kommentarer som ligger nær hverandre antas å være like i innholdet. Ved å bruke dette som vår grunnlinje, kan vi kartlegge hvilken som helst vilkårlig kommentarseksjon og etablere den generelle responsen på det aktuelle emnet.
Vi trekker en tilfeldig nettbasert kommentarseksjon med 386 kommentarer og sammenligner våre nye resultater med kjente kontroversielle emner. Dette kan gjøre det mulig for oss å analysere kommentatorers hovedinteressepunkter, spredning av kommentarenes innhold og utvikling av kommentartrådene over tid (f.eks. spore tråder fra politiske diskusjoner helt til personangrep).
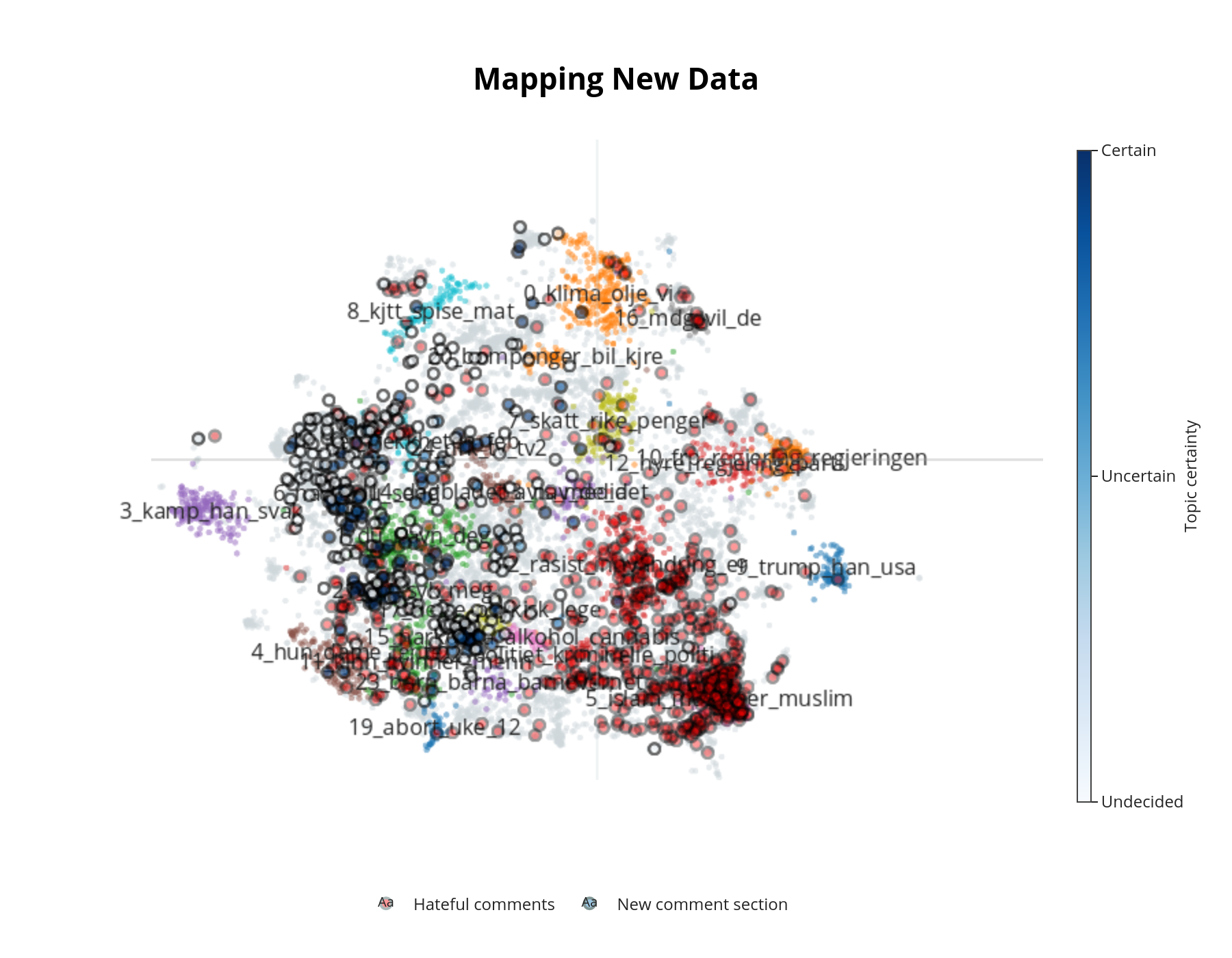
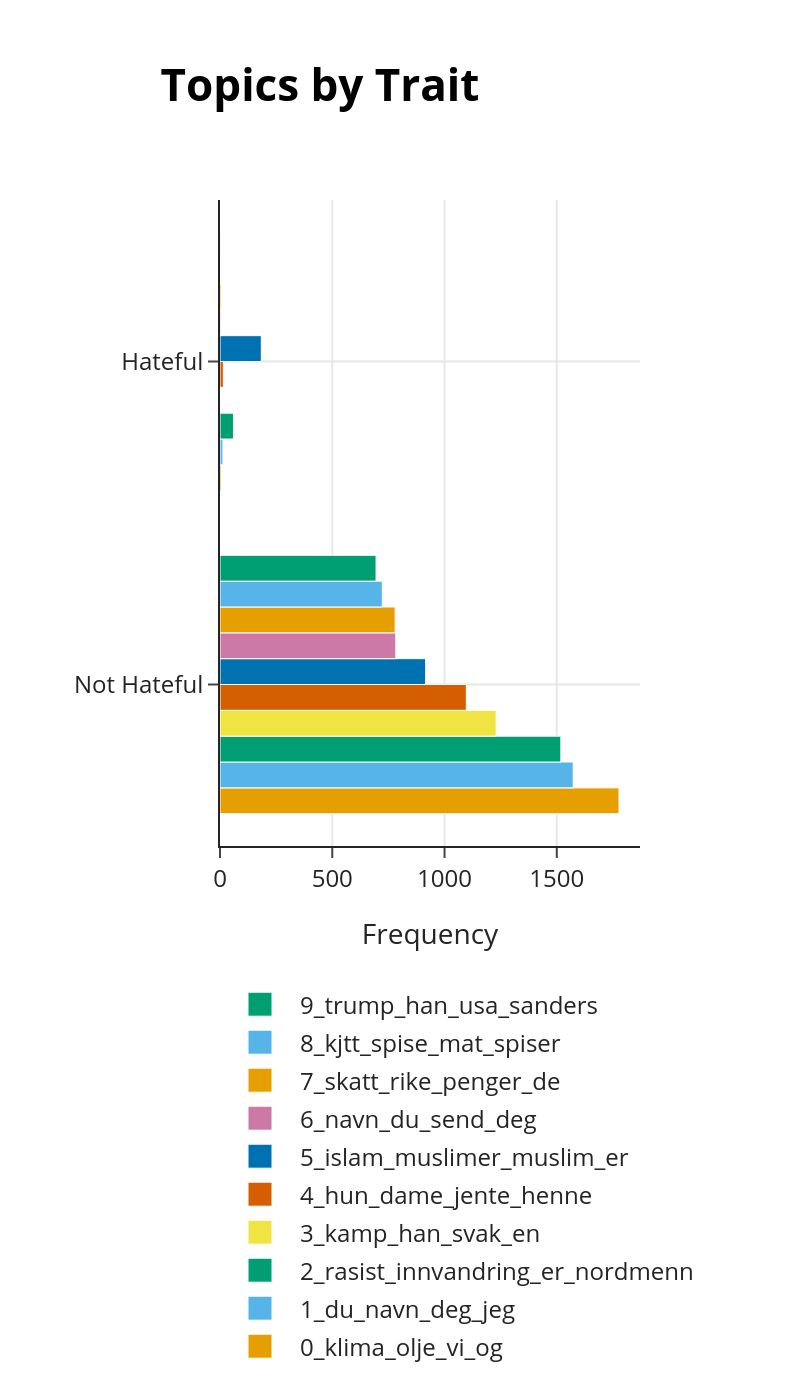
Figur 6 illustrerer vår prøvetatte kommentarseksjon sammenlignet med kjente hatefulle kommentarer. Vi finner at kommentarseksjonen ikke er betydelig påvirket av de mest kontroversielle emnene. Emnene inkluderer sykdom, psykiatri, narkotika og kommentarresponser (gjennom nøkkelordet “NAVN”). En potensiell endring mot andre irrelevante emner vil kunne bli raskt gjenkjent og, hvis ønskelig, moderert av en automatisert eller menneskelig moderator.
Ved å lokalisere trender på en visuell måte, kan man raskt vurdere kommentarfelt samt hvordan responsen endres over tid. Dermed kan man bedre bestemme når og hvordan innhold i offentlige debattfora nærmer seg kontroversielle emner og følge prosessen med eskalering i sanntid. Anonymiserte brukerdata kan spores over tid og brukes i en prediktiv sammenheng, noe som genererer nyttig tilbakemelding for både aktive- og inaktive deltakere i kommentarfeltet, samt for forfattere og moderatorer som administrerer siden. Innholdsmoderering kan forbedres ved å gi emne- og kommentatortrender sammen med det potensielt støtende innholdet som er tilgjengelig, noe som gjør det mulig å sortere og prioritere. Vi ønsker å forenkle moderering, samtidig som vi øker nærheten til ditt publikum.
Medietilsynet (2021) Delrapport 2: Sjikane via internett, og konsekvenser dette har for demokrati og deltakelse. Available at: https://www.medietilsynet.no/globalassets/dokumenter/rapporter/2021-kritisk-medieforstaelse/210427-kmf-2021-delrapport-2-sjikane-og-hat.pdf (Accessed: 10 January 2023).
Reimers, Nils, og Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv, 27. august 2019. arXiv.org, http://arxiv.org/abs/1908.10084.
Grootendorst, Maarten. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv, 11. mars 2022. arXiv.org, http://arxiv.org/abs/2203.05794.